Евгений Ющук. Конкурентная разведка.
На главную страницу сайта "Конкурентная разведка"
Управление репутацией в Интернете, в том числе борьба с негативом в Интернете
Интернет-форумы по конкурентной разведке
Организация конкурентной разведки на предприятии
Работа с людьми в конкурентной разведке
Интернет и компьютеры в конкурентнойразведке
Дополнительные возможности поиска в Интернете для конкурентной разведки
Блоги и блогосфера в конкурентной разведке
Инструменты анализа сайта для конкурентной разведки
Фотохостинги, не требующие регистрации, для конкурентной разведки
Исследование графических файлов в конкурентной разведке
Полезные ресурсы по конкурентной разведке
Официальная информация по предприятиям и гражданам в открытых источниках : Россия, Украина, Беларусь
Анонимное посещение сайта в конкурентной разведке
Плагины к браузеру Mozilla firefox, рекомендованные специалистами конкурентной разведки
Одноразовые почтовые ящики для конкурентной разведки
ПРИМЕРЫ РАССЛЕДОВАНИЙ, ПРОВЕДЕННЫХ ЕВГЕНИЕМ ЮЩУКОМ:






*
«Правый сектор» — организация, запрещенная в России по
решению Верховного суда
Сбор информации с "закрытых" форумов Невидимого Интернета. На примере экстремистских групп. Конспект-перевод статьи из NEW SCIENTIST.
Автор конспекта-перевода: Евгений Ющук
Авторы статьи "A Focused Crawler for Dark Web Forums" ( "Web spy software hacks into secretive online forums") в оригинале : Tianjun Fu, Ahmed Abbasi, Hsincun Chen.
В оригинале статья почти вдвое длиннее, поэтому тем, кто хочет прочесть ее всю, лучше читать в оригинале. Я перевел только то, что было интересно лично мне. Многое переведено не дословно, хотя и близко к тексту оригинала. Рисунки - из оригинального текста.
Работы в области целевых или тематически-ориентированных пауков, проводились Chakrabarti, Van Den Berg, & Dom, [1999]; Pant, Srinivasan, & Menczer, [2002]
Большинство ранних пауков концентрировались на сборе информации со статических страниц, причем англоязычных и выложенных открыто. Это страницы, так называемого, Видимого Интернета. Если конфигурировать паука для сбора информации с форумов Невидимого Интернета, приходится сталкиваться с несколькими серьезными проблемами. Одна из главных – доступ к материалам форума. Интернет-форумы динамичны и часто требуют регистрации участника. Нередко они и без умысла со стороны владельцев являются частью Невидимого Интернета (это отражено в работах Florescu, Levy, & Mendelzon, [1998]; Raghavan & Garcia-Molina, [2001]).
Форумы содержат статические и динамические текстовые файлы, архивные файлы, и различные формы мультимедийного контента (т.е., изображения, аудио и видео файлы). Сбор столь многообразного контента создает массу проблем, которые не могут быть решены стандартными пауками, ориентированными на текстовый контент. Второй важной проблемой является маскировка паука для обеспечения возможности повторной работы на форуме, т.к. при идентификации паука администраторами форума, он может быть заблокирован. Поэтому паук, нацеленный на работу в Форумах Невидимого Интернета должен применять несколько разных типов маскировки при просмотре обновлений контента.
В этом исследовании мы предлагаем варианты развития целевых пауков, предназначенных для работы в форумах Невидимого Интернета. Наша система управления пауками позволяет расширить и углубить обход форумов. Она основана на идентификаторах в адресной строке (url), якорных словах, уровнях гиперссылок. Наша система включает также элементы, которые позволяют преодолеть вышеупомянутые проблемы с доступом, многоязычностью и многовариантностью контента.
Для обеспечения доступа паука на форум, мы используем помощь человека – т.н. «human-assisted approach» (это отражено в работах Raghavan & Garcia-Molina, [2001]). Наша система включает также возможность настройки параметров паука и прокси-серверов для улучшения возможности проникновения на форумы. Пауки используют анализ url’ов, того, чтобы проводить тематический поиск новых форумов и материалов в автоматическом режиме, независимо от языка, на котором общаются на форуме.
Фрагмент работы Raghavan & Garcia-Molina http://www10.org/cdrom/posters/p1049/index.htm .
"A number of recent studies [1,2,3] have noted that a tremendous amount of content on the Web is dynamic. However, since current-day crawlers only crawl the publicly indexable Web [2], much of this dynamic content remains inaccessible for searching, indexing, and analysis. The hidden Web is particularly important, as organizations with large amounts of high-quality information (e.g., the Census Bureau, Patents and Trademarks Office, News media companies) are placing their content online, by building Web query front-ends to their databases.
Crawling the hidden Web is a very challenging problem for two fundamental reasons: (1) scale (a recent study [1] estimates the size of the hidden Web to be about $500$ times the size of the publicly indexable Web) and (2) the need for crawlers to handle search interfaces designed primarily for humans.
We address these challenges by adopting a task-specific human-assisted approach to crawling. Specifically, we selectively crawl portions of the hidden Web, extracting content based on the requirements of a particular application or task. We also provide a framework that allows the human expert to customize and assist the crawler in its activity".
Доступность
Огромная часть Интернета генерируется динамически. Часто контент такого рода требует предварительной авторизации пользователя, заполнения каких-то форм, регистрации (Raghavan & Garcia-Molina, 2000). Это заставляет отнести большую часть интернет-ресурсов к Невидимому Интернету. Одно из исследований показало, что Невидимый Интернет содержит в 400-500 раз больше информации, чем Видимый (Bergman, [2000]; Lin & Chen, [2002]).
Технология автоматического заполнения форм не является решением проблем с Форумами в Невидимом интернете, т.к. там часто требуется логиниться.
Решением проблемы доступа к Невидимому Интернету может быть подход, когда робот сфокусирован на определенной тематике, и на некоторых этапах ему помогает человек. Это полуавтоматическая работа: когда помощь эксперта обеспечивает доступ пауку к контенту, а далее паук обрабатывает его сам. Степень задействования человека зависит от сложности доступа на форум. Например, многие форумы требуют стандарно заполнить адрес электронной почты, а это легко автоматизировать. Но есть и такие процедуры, которые пройти может пока только человек.
Типы собираемой информации
Форумы создают паукам специфические трудности. Например, в форумах нет централизованного оглавления (Glance et al., [2005a]). Более того, приходится создавать специальные филтры, которые позволяют выделить из информационного массива разного рода метаданные – например, авторов, время выхода поста, разного рода служебные сообщения и т.п. Такие фильтры нужны для того, чтобы впоследствии проводить повторное сканирование форума, забирая только обновившуюся информацию.
BoardPulse (Glance et al., [2005a]) – система для сбора сообщений с интернет-форумов. Она состоит из двух компонентов – паука и фильтра. Limanto, Giang, Trung, Huy, and He ([2005]) создали движок для сбора информации с форумов, который включает паука, генератор фильтров и экстрактор (который применяет сгенерированные фильтры к форуму). Yih, Chang, and Kim ([2004]) создали онлайновую систему по работе с данными форумов, состоящую из паука и экстрактора. Их система уже имела точную направленность – искала материалы, связанные с предложениями и промо-акциями интернет-магазинов.
Проект NetScan (Smith, [2002]) собирал и визуализировал миллионы страниц в группах USENET.
RecipeCrawler (Li, Meng, Wang, & Li, [2006]) был нацелен на сбор рецептоа по кулинарии из самых разных источников., в т.ч. и из Интернет-Форумов. Как и BoardPulse, RecipeCrawler для сбора информации использовал паука и фильтр.
Guo et al. ([2006]) предложили паука, который шел по форуму, формируя маршрут на основе иерархии его страниц – подобно тому, как это делает обычный пользователь. Он использовал идентификаторы в тексте страниц и url’е для прокладки своего маршрута.Все вышеперечисленные системы были ориентированы на работу с открытыми Интернет-ресурсами. Они не были ориентированы на работу с Форумами в Невидимом Интернете. Соответственно, они не решали проблем первичного и повторного доступа на форум.
Разнообразие контента
Размеры мультимедийных файлдов, как правило, намного больше, чем текстовых. Значит, требуется больше времени на их скачивание и часто будут прерывания по тайм-ауту. Heydon and Najork ([1999]) извлекали все MIME типы файлов (включая изображения, видео, аудио, и .exe) - с помощью Mercator crawler. Они отметили, что при сборе таких файлов резко возрастает время работы и удваивается средний размер файла, по сравнению с извлечением HTML-файлов. Поэтому многие другие исследователи, как правило, игнорировали мультимедийный контент.
Метки в URL
Aggarwal, Al-Garawi, and Yu ([2001]) отмечали четыре категории идентификаторов, которые надо анализировать пауку при скачивании материалов. Это гиперссылки, текст в анкоре и в url, и уровень страницы (ее удаленность от главной).
Многие исследования включали в работу внутренние, входящие и исходящие ссылки (Pant et al., [2002]).
Тематические пауки используют семантическое ядро страницы, для определения того, к какому разделу ее отнести. Например, Srinivasan et al. ([2002]) использовал семантическое ядро страницы для отнесения текста к категории «биология-медицина» при работе со своим тематическим пауком. Но, при всем том, что работа с текстом очень эффективна, она сильно зависима от языка и затруднительна при работе со ресурсами, где языки разные.
Слова-идентификаторы в url. Они удобны тем, что снижают зависимость качества работы паука от языка, на котором идет общение на странице. Часто их сочетают с анализом слов на самой странице.
Еще один важный критерий для поиска нужных страниц – это удаленность страницы от главной. Определение этого параметра позволяет лучше спланировать путь паука на форуме и избежать посещения нецелевых страниц. Выявление, какие страницы находятся в одном-двух шагах от цели, позволяют улучшить поиск, не перегружая его при этом заведомо бесполезными результатами.
Процедура обновления контента.
Есть два принципиальных подхода к сбору обновлений на форумах. Первый – периодическое повторное сканирование страниц. Это проще технически организовать, но требует больших затрат времени и ресурсов. Хотя и дает более полный результат.
Второй – сбор только того контента, который появился дополнительно, с момента прошлого посещения (Glance et al., [2005a]; Li et al., [2006]; Yih et al., [2004]). «Дополняющие» пауки требуют настройки фильтра, который бы определял обновившийся контент – например, на страницах «Непрочитанное», которые формируются для каждого залогиненного пользователя.
«Пробелы и вопросы в поиске на форумах»
Вот несколько основных поисковых «пробелов», которые выявлены в обзорах литературы по данному вопросу.
1. Целенаправленный поиск в Невидимом Интернете
Довольно мало есть пауков, котрые сконфигурированы конкретно для поиска в Невидимом Интернете. Большинство существующих пауков предназначено для работы в Видимом Интернете. Большинство проведенных ранее работ относилось к вопросу сбора информации. А вопрос определения тематических ресурсов, на которых надо проводить сбор, мало освещен. Мы не нашли ни одной работы, в которой говорилось бы об автоматическом создании каталогов, которые объединяют в себе форумы и группы экстремистской или агрессивной направленности.
2. Большинство предшествующих исследований фокусировалось на индексируемых (т.е. текстовых) файлах.
Большие мультимедийные файлы (например, видео) могут «весить» сотни мегабайт. Это приводит к тому что при их скачивании часто происходят сбои, что ведет к неполному скачиванию или к прерыванию скачивания. Кроме того, проблематично индексировать мультимедийные файлы. Тем не менее, необходимость в поиске и скачивании таких файлов очевидна и эту проблему надо решать.
3. Маскировка паука на форуме
Предыдущие исследования не решали вопросов маскировки активности, особенно при повторном посещении форума. Однако при работе на форумах Невидимого интернета приходится решать проблему скрытности, иначе просто не получится работать там.
4. Выбор стратегии улучшения качества повторного сканирования (в поисках изменений).
«Периодические» пауки улучшают качество собранной информации за счет того, что просто-напросто многократно сканируют все страницы форума. Это приемлемо для открытых форумов, но неприемлемо для Форумов Невидимого Интернета.
«Дополняющие» пауки, напротив, могут улучшить качество сбора информации, не повторяя в полной мере сбор информации. Необходимо сравнить эффективность обоих типов сканирования, чтобы определиться с тем, какую же стратегию надо развивать.
Поисковые вопросы.
1: Как эффективно найти Форумы Невидимого интернета и получить доступ на них?
2: Как можно эффективно обнаружить и вытащить с форумов контент (в т.ч. мультимедийный)?
3: Какая система поиска обновлений (периодическая или дополняяющая) наиболее применима на Форумах Невидимого Интернета? Как можно улучшить процесс поиска обновлений информации?
4: Как анализ собранной информации улучшить понимание нами этих онлайновых сообществ?
Предложенная система сбора информации на форумах
Наша система включает в себя модуль доступа, который допускает, при необходимости, участие человека для доступа на форум (например, при регистрации). Кроме того, система использует множество меняющихся прокси-серверов.
Наш модуль анализа адресов позволяет работать, не впадая в зависимость отязыка, на котором веется общение на форуме. Мы фокусировались на группах из трех регионов: Собственно США, Ближний Восток, И Латинская Америка/Испания
Мы предложили также «Дополняющего» паука, который использовал фильтры для определения подмножества веток форума, с которых необходимо собрать контент. Наша система также анализировала логии паука и повторяла загрузки, если они окончились неудачей. И, наконец, наша система следила за тем, чтобы не дублировались загрузки мультимедийных файлов.
Механизм улучшения повтороного сбора информации.
Учитывая специфику Форумов Невидимого интернета (прежде всего – заведомо агрессивный настрой против действий пауков), применялись дополнительные приемы маскировки. Например, тщательно контролировалось количество пауков на форуме, количество перемен прокси на каждого паука, и ряд других настроек, позволяющих замаскировать действия на форуме. По сути, это эвристический метод противодействия выявлению паука админами форума.
«Дополняющие» пауки в вопросах сбора данных»
Мы планируем оценить эффективность нашего Дополняющего паука по сравнению с периодическим пауком. Дополняющий паук, очевидно, будет более эффективен, если говорить о времени сбора информации и об обновлениях. Но Периодический паук, а счет того, что он повторно сканирует одни и те же страницы, может более точно показывать изменения на этих страницах. Наблюдение за работой пауков, которые используют обе эти стратеги подхода к поиску обновлений, позволяет глубже понять, какая из этих стратегий предпочтительнее для целей мониторинга Форумов Глубокого Интернета.
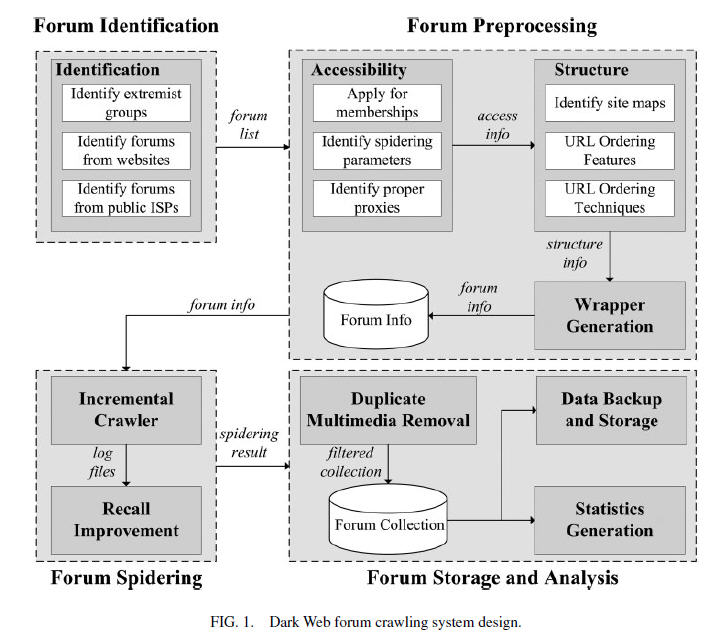
|
Forum Identification: Идентификация форума. Составление списка экстремистских форумов для паука; |
|
Forum preprocessing: Подготовительные работы – включают в себя оценку и составление маршрутов для работы паука а также создание и настройку фильтров для работы на форуме. |
|
Forum spidering: Непосредственно сбор информации с форума. Включает в себя работу Дополняющего паука и механизм улучшения повторного сбора информации. |
|
Forum storage andanalysis: Сохранение и анализ информации с форума. |
Идентификация форума - Forum Identification
Идентификация форума состоит из трех этапов.
Выявление групп экстремистской направленности.
Источники для выявления экстремистских групп непосредственно в США: Anti-Defamation League (ADL), FBI, Southern Poverty Law Center (SPLC), Militia Watchdog (MW), и Google Web Directory (GD) (в качестве дополнения).
Источники для выявления международных групп экстремистской направленности включают: U.S. Committee for a Free Lebanon (USCFAFL), Counter-Terrorism Committee (CTC) of the U.N. Security Council (UN), U.S. State Department report (US), OfficialJournaloftheEuropeanUnion (EU), а также официальные государственные отчеты из Великобритании (UK), Австралии (AUS), Японии (JPN), Китайской Народной Республики (CHN).
Из-за проблем языкового характера и региональной специфики, мы сосредоточились на изучении трех регионов: NСеверная Америка (англоязычные ресурсы), Латинская Америка (испаноязычные ресурсы), и Ближний Восток. Все эти группы имеют важное социальное и политическое значение.
Кроме того, работа с Форумами Невидимого Интернета, относящимися к этим группам, помогает лучше понять и различие между группами. Кроме и так очевидных различий по языку, эти группы обнаружили отличия и в тенденциях во внешнем оформлении своих Интернет-страниц, и разное пользовательское поведение. (Abbasi & Chen, [2005]). Эти находки в значительной степени упростили сбор информации и интерпретацию полученных данных.
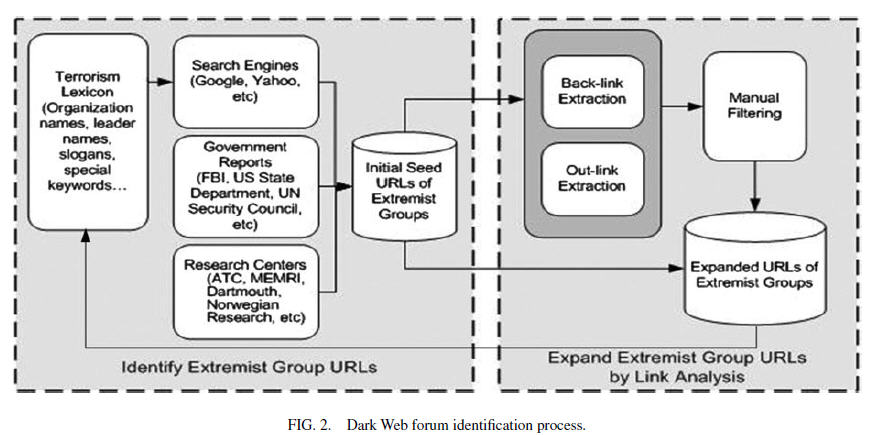
Выявление форумов на экстремистских сайтах
Мы установили основные элементы адресов экстремистских групп и затем использовали анализ ссылок для целей расширения списка экстремистских сайов – как показано на рис.2.
Первоначальный набор адресов (url’ов) набирается из трех источников:
- Из поисковых машин, куда водятся запросы, содержащие лексику экстремистских групп. – например. Названия, имена лидеров, слоганы и специфические слова, которыми пользуются экстремисты.
- Мы использовали данные из государственных отчетов.
- Мы проработали данные исследовательских центров.
Дальнейший анализ ссылок позволил расширить этот первоначальный перечень адресов. Анализ обратных ссылок в Гугле, как показала практика, оказался очень эффективным (Diligenti et al., [2000]). Внешние ссылки на первоначальные ресурсы, и дальнейший анализ внутренних ссылок на этих ресурсах позволил еще дополнить полученную ранее информацию.
Выявленные таким образом форумы были вручную проверены, специалистами по работе с доменами. После этого было установлено, какие форумы относятся к Невидимому Интернету – и именно их взяли в дальнейшее исследование.
Выявление форумов, расположенных на крупнейших вэб-сервисах.
Мы уделили особое внимание группам, расположенным в крупных социальных сетях – например, группам в MSN и AOL Такие группы – если они относились к невидимому Интернету – также были включены нами в список форумов.
Эти шаги позволяли выявить нужные нам форумы, относящиеся к Невидимому Интернету. После того, как форум обнаружен, надо решить несколько важных подготовительных задач, для того, чтобы начать сбор информации с форумов. Требуется определить структуру форума, чтобы потом правильно настроить паука.
Подготовительные работы на фоуме.
Подготовительные работы включают в себя:
- доступ на форум (получение и поддержание в рабочем состоянии доступа на форум)
-определение структуры форума (составление карты форума, маршрутов паука по форуму)
- настройку фильтров
Доступ на форум
Регистрация аккауниа.
Многие форумы Невидимого Интернета (![]() 30-40%) не позволяют анонимный доступ (Zhou et al., 2006). Для доступа к информации таких форумов, вы должны завести аккаунт с логином и паролем и отправить запрос администратору форума, а затем подождать одобрения им вашей регистрации.На некоторых форумах админы очень разборчивы.Может потребоваться пара повторных обращений к мейлу, чтобы регистрация состоялась Для работы га таких форумах помощь человека категорически необходима. Но даже при этом, на некоторые форумы доступ получить невозможно. Наши исследования нескольких сотен форумов Невидимого Интернета показали, что на 10% форумов доступ в принципе невозможно получить.
30-40%) не позволяют анонимный доступ (Zhou et al., 2006). Для доступа к информации таких форумов, вы должны завести аккаунт с логином и паролем и отправить запрос администратору форума, а затем подождать одобрения им вашей регистрации.На некоторых форумах админы очень разборчивы.Может потребоваться пара повторных обращений к мейлу, чтобы регистрация состоялась Для работы га таких форумах помощь человека категорически необходима. Но даже при этом, на некоторые форумы доступ получить невозможно. Наши исследования нескольких сотен форумов Невидимого Интернета показали, что на 10% форумов доступ в принципе невозможно получить.
Определениесоответствующихнастроекпаука.
Настройки паука – такие как количество подключений, интервал между скачиваниями, таймаут, скорость т.д. – должны позволять скачать нужную информацию, и при этом не подпасть под механизмы блокировки, которые установлены на форуме. Принимая во внимание, что мультимедийные файлы на форумах могут быть очень большими, параметры паука должны позволять скачивать такие файлы даже с медленных серверов. Но это повышает риск быть заблокированными по ip-адресу. Поэтому мы использовали прокси-серверы – для обеспечения анонимности и, вместе с тем, для повышения вероятности не избежать блокировки на форуме.
Выборпрокси-серверов.
Мы обновляли список прокси серверов периодически, пользуясь разными источниками. Прокси брались с бесплатных публичных площадок – таких, как www.xroxy.com и www.proxy4free.com Кроме того, паук менял user-agent'а и игнорировал «robot exclusion protocol», хотя надо отметить, что почти никто не использовал файл robots.txt на форумах невидимого Интернета.
Структура форума
Составление карты форума.
Прежде всего, мы оцениваем структуру форум с помощью его встроенных механизмов. Glance et al. ([2005a]) отмечали, что, хотя форумы имеют механизмы, позволяющие только вручную проводить такое исследование, эти механизмы удобны и информативны. Как правило, форумы имеют древовидную структуру и состоят из подфорумов, тем (веток) и сообщений.(Glance et al., [2005a]; Yih et al., [2004]). Они содержат также дополнительную информацию – такую, как интерфейс для постинга сообщений, поиск, вывод на печать, рекламу, календарь. все они не нужны для целей нашего исследования.
Кроме того, на форумах есть страницы, которые содержат, например, все сообщения одного автора. Сбор такого рода информации приведет к дублированию контента, значительно увеличит врмя сбора информации и повысит вероятность обнаружения и последующей блокировки паука админами форума.
Правильный выбор идентифкаторов адресной строки позволяет собирать только нужную информацию, причем быстро и максимально скрытно для наблюдателей, т.к. при этом имитируется поведение обычного посетителя форума.
На что обращали внимание в адресной строке.
Наша система пауков основана на двух основных идентификаторах – метках в адресе и уровне страницы. Метки в адресе – это, например, такие слова, которые характеризуют посты в форуме: ![]() board,
board,![]()
![]() thread,
thread,![]()
![]() message,
message,![]() и т.п. (Glance et al., [2005a]). Кроме того, метки, которые мы принимали во внимание – это, например, доменные имена других сайтов или имена файловых хранилищ. Посторонние сайты интересны тем, что в таком случае они, как правило, содержат мультимедийные файлы (на форум много их не выложишь и удобно не продемонстрируешь).
и т.п. (Glance et al., [2005a]). Кроме того, метки, которые мы принимали во внимание – это, например, доменные имена других сайтов или имена файловых хранилищ. Посторонние сайты интересны тем, что в таком случае они, как правило, содержат мультимедийные файлы (на форум много их не выложишь и удобно не продемонстрируешь).
В адресной строке еще есть метки, которые принимаются во внимание – это расширения файлов (![]() .jpg
.jpg![]() и
и ![]() .wmv
.wmv![]() ). Важны также фразы в адресе – например,
). Важны также фразы в адресе – например, ![]() sort=voteavg
sort=voteavg![]() and
and ![]() goto=next
goto=next![]() , но они все же неуникальны именно для форумов и поэтому имеют вспомогательное значение.
, но они все же неуникальны именно для форумов и поэтому имеют вспомогательное значение.
Уровень страницы важен потому, что мултимедийные файлы часто расположены на посторонних серверах. И потому оказываются далеко от исходного форума. «Объяснение» пауку, как прокладывать к ним маршрут, позволяет автоматизировать поиск таких страниц и получение информации с них.
Далее в статье приводилась статистика собранных файлов и анализ этих данных, а также анализ логови оценка проделанной работы. Я не стал переводить эти подробности. Перейду сразу к разделу «Заключение».
Заключение.
В этой работе мы усовершенствовали пауков для целевого сбора информации с Форумов Невидимого Интернета. Мы использовали механизм доступа на форум при помощи человека, и это дало нам 90-процентный успех по проникновению на форум.
10% форумов нас не впустили вообще.
Наши пауки использовали идентификаторы адресной строке, которые позволяли определять нужные страницы форумов (и вообще форумы) даже в тех случаях, когда контент там был многоязычным.
Кроме того, мы использовали собственные стратегии передвижения по форуму и стратегии создания фильтров, чтобы поддерживать «Дополняющую» систему скачивания обновленной информации – т.е.. чтобы находить и скачивать только то, что обновилось, а не вообще скачивать повторно всё без исключения. Именно такой подход в агрессивной среде экстремистских дискуссионных групп позволял нам оставаться незамеченными и не доводил о блокировки нашей активности.
Наша система была апроьирована на 109 форумах в трех основных макрорегионаз (США, Латинская Америка, Ближний Восток) и на разных языках. Полученные данные мы использовали как кейс для анализа контента. Мы уверены, что наша система, позволяющая с высокой степенью вероятности проникать на «закрытые» форумы, поможет лучше понимать активность экстремистских групп вне Интернета.
Мы, кроме того, определили несколько важных направлений для развития этой темы в дальнейших исследованиях. В частности, планируем улучшить механизм проникновения на Интернет-форумы. Чтобы повысить процент успешных входов туда. Планируем также распространить активность наших пауков на сбор контента с блогов и из чатов. И наконец, планируем улучшить технику сортировки собранного мультимедиа, чтобы получать более релевантные результаты при поиске среди собранных мультимедийных файлов и файлов изображений.
Список литературы к статье представляет собой, как мне кажется, отдельную ценность. Привожу его так, как он дан в оригинале статьи.
Abbasi, A., & Chen, H. (2005). Identification and comparison of extremist-group Web forum messages using authorship analysis. IEEE Intelligent Systems , 20(5), 67-75. Links
Aggarwal, C.C., Al-Garawi, F., & Yu, P.S. (2001). Intelligent crawling on the World Wide Web with arbitrary predicates. In Proceedings of the Tenth World Wide Web Conference (pp. 96-105). New York: ACM Press.
Baeza-Yates, R. (2003). Information retrieval in the Web: Beyond current search engines. International Journal of Approximate Reasoning , 34, 97-104. Links
Barbosa, L., & Freire, J. (2004). Siphoning hidden-Web data through keyword-based interfaces. In Proceedings of the 19th Brazilian Symposium on Databases (pp. 309-321). Brasilia, Brazil:SBBD.
Bergman, M.K. (2000). The deep Web: Surfacing hidden value. Retrieved March 3, 2010, from http://quod.lib.umich.edu/cgi/t/text/text-idx?c=jep;view=text;rgn=main;idno=3336451.0007.104
Burris, V., Smith, E., & Strahm, A. (2000). White supremacist networks on the Internet. Sociological Focus , 33(2), 215-235. Links
Chakrabarti, S., Punera, K., & Subramanyam, M. (2002). Accelerated focused crawling through online relevance feedback. In Proceedings of the 11th International World Wide Web Conference (pp. 148-159). New York: ACM Press.
Chakrabarti, S., Van Den Berg, M., & Dom, B. (1999). Focused crawling: A new approach to topic-specific resource discovery. In Proceedings of the Eighth World Wide Web Conference (pp. 1623-1640). New York: ACM Press.
Chalmers, M., & Chitson, P. (1992). Bead: Explorations in information visualization. In Proceedings of the 15th Annual International ACM/SIGIR Conference (pp. 330-337). New York: ACM Press.
Chau, M., & Chen, H. (2003). Comparison of three vertical search spiders. IEEE Computer , 36(5), 56-62. Links
Chen, H. (2006). Intelligence and security informatics for international security: Information sharing and data mining. London: Springer Press.
Chen, H., & Chau, M. (2003). Web mining: Machine learning for Web applications. Annual Review of Information Science and Technology , 37, 289-329. Links
Chen, H., Chung, Y., Ramsey, M., & Yang, C. (1998a). A smart itsy bitsy spider for the Web. Journal of the American Society for Information Science , 49(7), 604-619. Links
Chen, H., Chung, Y., Ramsey, M., & Yang, C. (1998b). An intelligent personal spider (agent) for dynamic internet/intranet searching. Decision Support Systems , 23(1), 41-58. Links
Cheong, F.C. (1996). Internet agents: Spiders, wanderers, brokers, and bots. Indianapolis, IN: New Riders. Cho, J., & Garcia-Molina, H. (2000). The evolution of the Web and implications for an incremental crawler. In Proceedings of the 26th International Conference on Very Large Databases (pp. 200-209). New York: ACM Press.
Cho, J., Garcia-Molina, H., & Page, L. (1998). Efficient crawling through URL ordering. Computer Networks and ISDN Systems , 30(1-7), 161-172. Links
Crilley, K. (2001). Information warfare: New battle fields terrorists, propaganda, and the Internet. In Proceedings of the Association for Information Management , 53(7), 250-264. Links
De Bra, P.M.E. & Post, R.D.J. (1994). Information retrieval in the World-Wide Web: Making client-based searching feasible. In Proceedings of the First World-Wide Web Conference (pp. 183-192). New York: ACM Press.
Diligenti, M., Coetzee, F.M., Lawrence, S., Giles, C.L., & Gori, M. (2000). Focused crawling using context graphs. In Proceedings of the 26th Conference on Very Large Databases (pp. 527-534). New York: ACM Press.
Ester, M., Grob, M., & Kriegel, H. (2001). Focused Web crawling: A generic framework for specifying the user interest and for adaptive crawling strategies. Retrieved March 3, 2010, from http://www.dbs.informatik.uni-muenchen.de/![]() ester/papers/VLDB2001.Submitted.pdf
ester/papers/VLDB2001.Submitted.pdf
Florescu, D., Levy, A.Y., & Mendelzon, A.O. (1998). Database techniques for the World-Wide Web: A Survey. SIGMOD Record , 27(3), 59-74. Links
Fu, T., Abbasi, A., & Chen, H. (2008). A hybrid approach to Web forum interactional coherence analysis. Journal of the American Society for Information Science and Technology , 59(8), 1195-1209. Links
Glance, N., Hurst, M., Nigam, K., Siegler, M., Stockton, R., & Tomokiyo, T. (2005a). Analyzing online discussion for marketing intelligence. In Proceedings of the 14th International World Wide Web Conference (pp. 1172-1173). New York: ACM Press.
Glance, N., Hurst, M., Nigam, K., Siegler, M., Stockton, R., & Tomokiyo, T. (2005b). Deriving market intelligence from online discussion. In Proceedings of the ACM Conference on Knowledge Discovery and Data Mining (pp. 419-428), Chicago. Glance,
N., Hurst, M., & Tomokiyo, T. (2004, May). BlogPulse: Automated trend discovery for weblogs. Paper presented at the 13th International World Wide Web Conference Workshop on Weblogging Ecosystem: Aggregation, Analysis, and Dynamics, New York, NY. Retrieved March 3, 2010, from http://www.blogpulse.com/papers/www2004glance.pdf
Glaser, J., Dixit, J., & Green, D.P. (2002). Studying hate crime with the Internet: What makes racists advocate racial violence? Journal of Social Issues , 58(1), 177-193. Links
Guo, Y., Li, K., Zhang, K., & Zhang, G. (2006). Board forum crawling: A Web crawling method for Web forum. In Proceedings of the Conference on Web Intelligence (pp. 745-748). Washington, DC: IEEE.
Gustavson, A.T., & Sherkat, D.E. (2004, August). Elucidating the Web of hate: The ideological structuring of network ties among White supremacist groups on the Internet. Paper presented at Annual Meeting of American Sociological Association, San Francisco, CA.
Heydon, A., & Najork, M. (1999). Mercator: A scalable, extensible Web crawler. In Proceedings of the International Conference on the World Wide Web (pp. 219-229). New York: ACM Press.
Lage, J.P., Da Silva, A.S., Golgher, P.B., & Laender, A.H.F. (2002). Collecting hidden Web pages for data extraction. In Proceedings of the Fourth International Workshop on Web Information and Data Management (pp. 69-75). New York: ACM Press.
Lawrence, S., & Giles, C.L. (1999). Searching the World Wide Web. Science , 280(5360), 98. Links
Leuski, A., & Allan, J. (2000). Lighthouse: Showing the way to relevant information. In Proceedings of the IEEE Symposium on Information Visualization (pp. 125-130). Washington, DC: IEEE.
Li, Y., Meng, X., Wang, L., & Li, Q. (2006). RecipeCrawler: Collecting recipe data from WWW incrementally. In Proceedings of the 7th International Conference on Web-Age Information Management (pp. 263-274). Washington, DC: IEEE.
Limanto, H.Y., Giang, N.N., Trung, V.T., Huy, N.Q., & He, J.Z.Q. (2005). An information extraction engine for Web discussion forums. In Special Interest Tracks and Posters of the 14th International Conference on the World Wide Web (pp. 978-979). New York: ACM Press.
Lin, K., & Chen, H. (2002). Automatic information discovery from the Invisible Web. In Proceedings of the International Conference on Information Technology: Coding and Computing (p. 332). Washington, DC: IEEE.
Menczer, F. (2004). Lexical and semantic clustering by Web links. Journal of the American Society for Information Science and Technology , 55(14), 1261-1269. Links
Menczer, F., Pant, G., & Srinivasan, P. (2004). Topical Web crawlers: Evaluating adaptive algorithms. ACM Transactions on Internet Technology , 4(4), 378-419. Links
Najork, M., & Wiener, J.L. (2001). Breadth-first search crawling yields high-quality pages. In Proceedings of the World Wide Web Conference (pp. 114-118). New York: ACM Press.
Ntoulas, A., Zerfos, P., & Cho, J. (2005). In Proceedings of the Fifth ACM/IEEE-CS Joint Conference on Digital Libraries (pp. 100-109). New York: ACM Press. Pant, G., & Srinivasan, P. (2005). Learning to crawl: Comparing classification schemes. ACM Transations on Information Systems , 23(4), 430-462. Links
Pant, G., & Srinivasan, P. (2006). Link contexts in classifier-guided topical crawlers. IEEE Transactions on Knowledge and Data Engineering , 18(1), 107-122. Links
Pant, G., Srinivasan, P., & Menczer, F. (2002, May). Exploration versus exploitation in topic driven crawlers. Paper presented at the Second World Wide Web Workshop on Web Dynamics, Honolulu, Hawaii. Retrieved March 2, 2010, from http://www.dcs.bbk.ac.uk/webDyn2/proceedings/pant\_topic\_driven\_crawlers.pdf
Raghavan, S., & Garcia-Molina, H. (2001). Crawling the hidden Web. In Proceedings of the 27th International Conference on Very Large Databases (pp. 129-138). New York: ACM Press.
Schafer, J. (2002). Spinning the Web of hate: Web-based hate propagation by extremist organizations. Journal of Criminal Justice and Popular Culture , 9(2), 69-88. Links
Sizov, S., Graupmann, J., & Theobald, M. (2003). From focused crawling to expert information: An application framework for Web exploration and portal generation. In Proceedings of the 29th International Conference on Very Large Databases (pp. 1105-1108). New York: ACM Press.
Smith, M. (2002). Tools for navigating large social cyberspaces. Communications of the ACM , 45(4), 51-55. Links
Srinivasan, P., Mitchell, J., Bodenreider, O., Pant, G., & Menczer, F. (2002, July). Web crawling agents for retrieving biomedical information. Paper presented at International Workshop on Agents in Bioinformatics (NETTAB), Bologna, Italy. Retrieved March 3, 2010, from http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.16.8948&rep=rep1&type=pdf
Whine, M. (1997). The governance of cyberspace: Politics, technology, and global restructuring. London: Routledge.
Yih, W., Chang, P., & Kim, W. (2004). Mining online deal forums for hot deals. In Proceedings of the Web Intelligence Conference (pp. 384-390). Washington, DC: IEEE. Zhou, Y., Reid, E., Qin, J., Chen, H., & Lai, G. (2005). U.S. extremist groups on the Web: Link and content analysis. IEEE Intelligent Systems , 20(5), 44-51. Links


————————————————

————————————————
————————————————

————————————————

————————————————

————————————————
————————————————

————————————————

————————————————

————————————————

————————————————
————————————————

————————————————

————————————————

————————————————

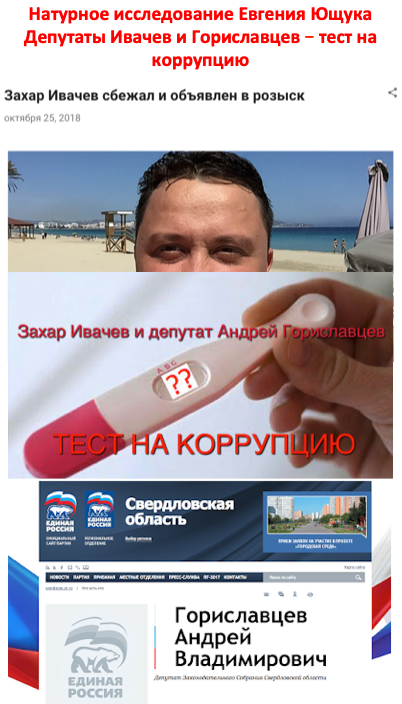
* «Правый сектор» — организация, запрещенная в России по решению Верховного суда
ХОТИТЕ УЗНАТЬ, ЭФФЕКТИВНЫ ЛИ МЕТОДЫ РАБОТЫ ЕВГЕНИЯ ЮЩУКА?
ПОСМОТРИТЕ МНЕНИЕ ГЕНПРОКУРАТУРЫ РФ:

(подробнее — здесь)
ИЛИ
ОБРАТИТЕ ВНИМАНИЕ НА ЭТОТ ФАКТ:

ИЛИ
ОЗНАКОМЬТЕСЬ С ЭТИМ КЕЙСОМ:

ИЛИ
ПОСЛУШАЙТЕ ОТЗЫВЫ НАШИХ ПРОТИВНИКОВ:
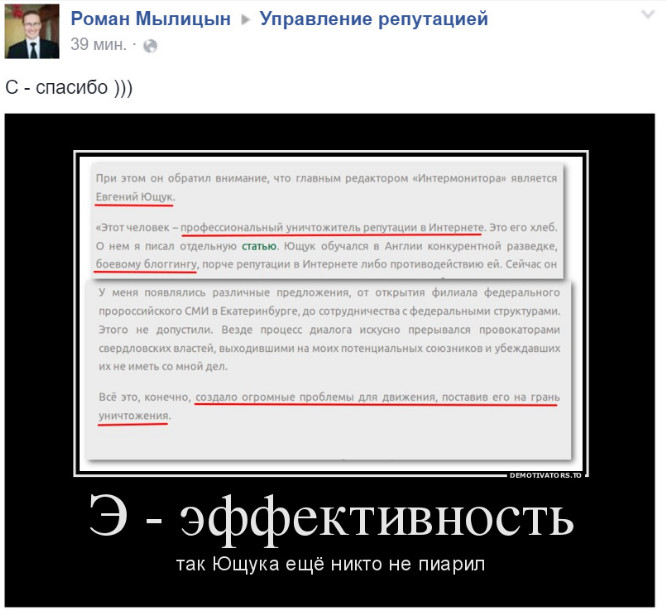
(подробнее — здесь)